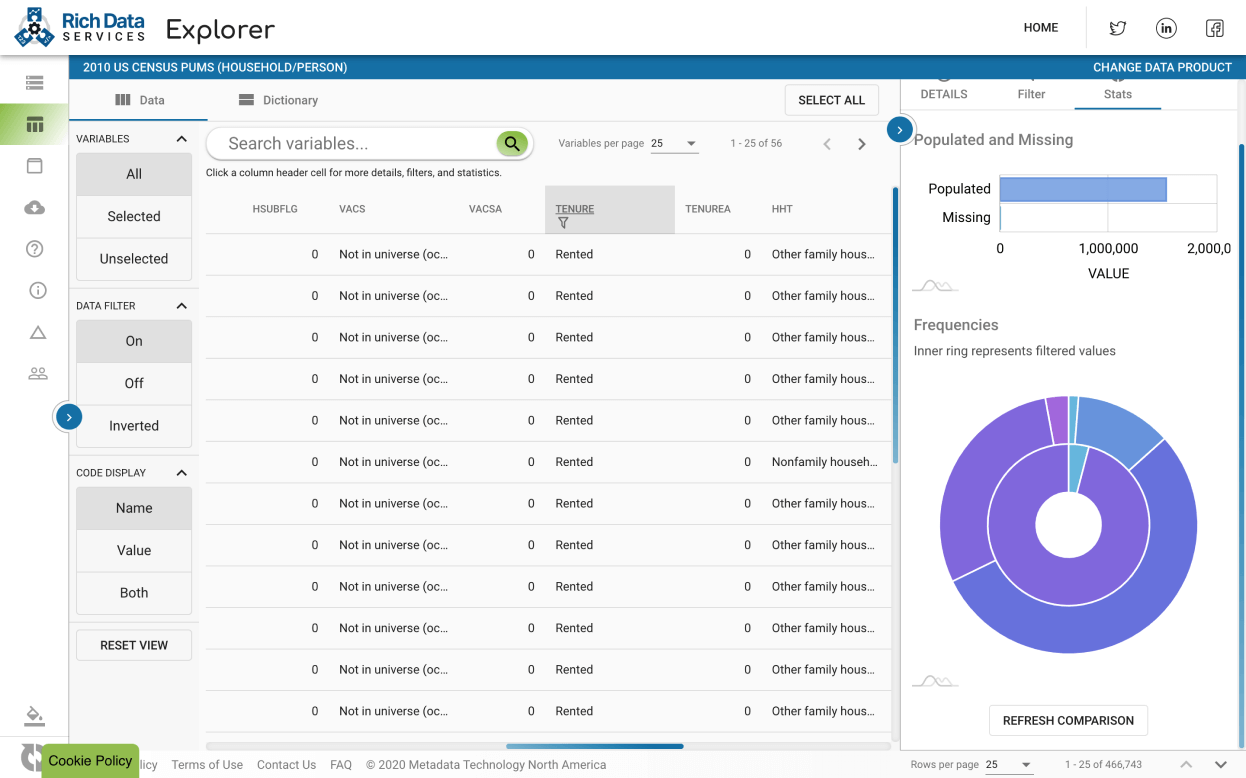
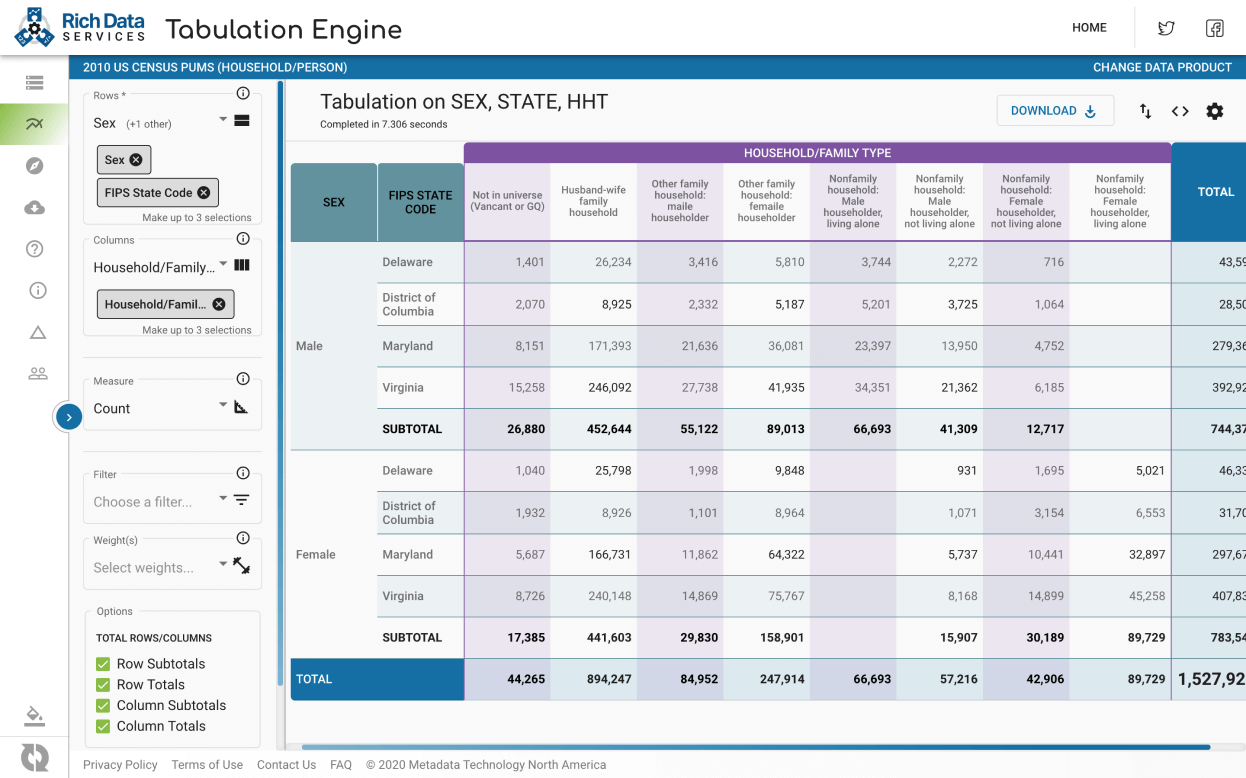
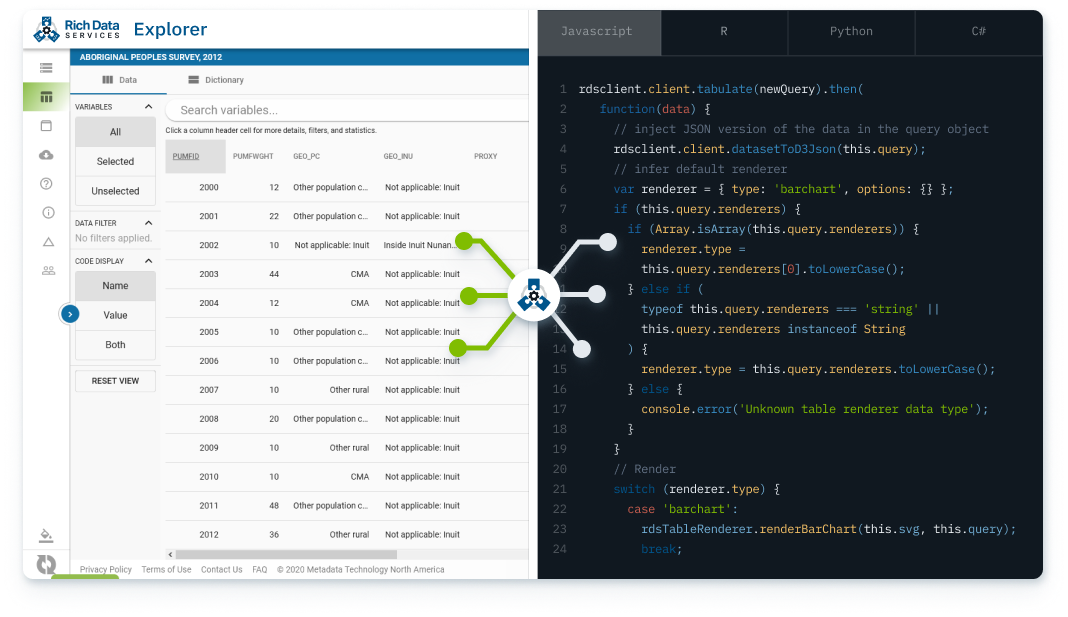
This Website, underlying services, and content herein, including all data, metadata, scripts, documentation, and resources, are provided to the public strictly for educational and academic research purposes. The content relies upon publicly available data from multiple sources that do not always agree. Metadata Technology North America Inc. hereby disclaims any and all representations and warranties with respect to the Website, including accuracy, fitness for use, and merchantability. You are responsible for determining the suitability of this data for your purposes. Reliance on the Website for medical, financial, or other kind of decision, or the use of the Website for commercial purposes, are strictly prohibited. If you do not agree with these terms, and to our general Website term and privacy policy, you may not access and use this Website.
 Watch our new video to see how easy it can be to gain access to the U.S. Small Business Administration Paycheck Protection Program (PPP) data using the Rich Data Services (RDS) API or web based applications.
Watch our new video to see how easy it can be to gain access to the U.S. Small Business Administration Paycheck Protection Program (PPP) data using the Rich Data Services (RDS) API or web based applications.